Deepseek: signal vs noise
2 min
The Chinese, non-listed company DeepSeek recently released a new AI model, and we took notice. What caught our attention was the low development cost, which didn't sit well with the markets. What can we learn from this release, and how should we manage our expectations?

Large Language Models (LLMs) don't grow on trees. These language models are created by processing massive amounts of data points (a training set) into a set of weights. These weights convert a user's input, for example, in a chatbot window, into a response. For the current generation of LLMs, the quality of these responses still varies between impressive and less impressive. However, the distribution is shifting towards the former, away from the latter, as better models emerge.
Capital expenditure (Capex)
How does this improvement happen? Brilliant minds refine the process from training set to weights. AI developers strike deals with, for example, publishers who provide unique, high-quality datasets. AI developers also learn from each other and adopt best practices. But above all, CEOs of major tech companies rely on the apparent golden rule: "more computing power = better models".
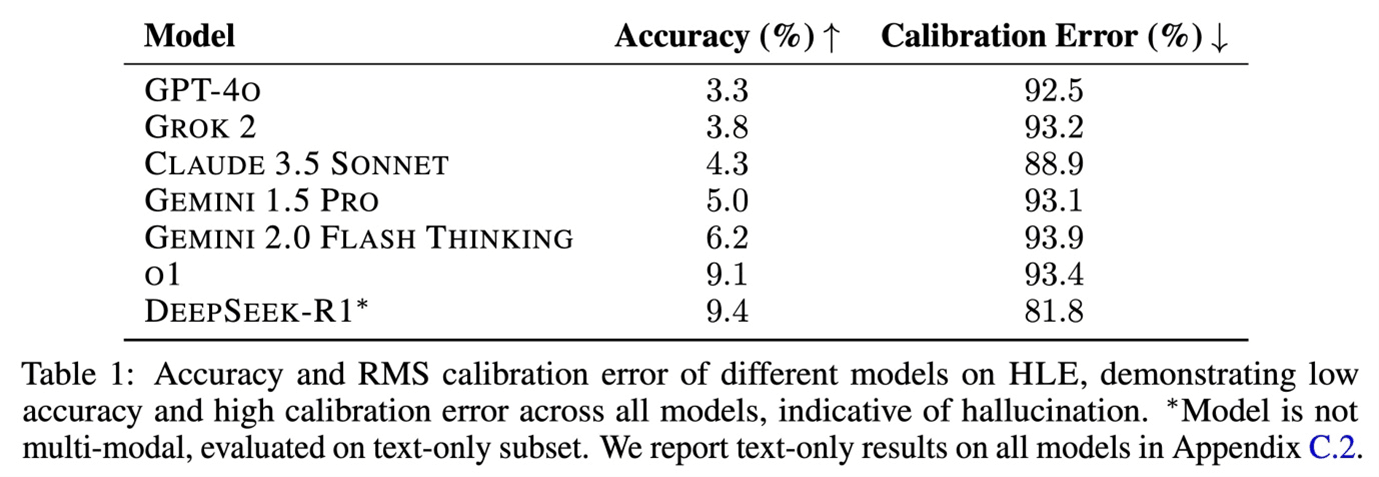
That's why massive amounts of money are flowing into the expansion of data centres, and tech players are suddenly investing in energy supply and even signing direct financial agreements with nuclear power plants. For the same reason, they're stockpiling graphics chips. It's precisely this assumption that DeepSeek seems to be debunking with its latest release. The estimated training cost: around $5 million. The cost is about 1% of what OpenAI and Meta would typically spend on similar projects.
Operational costs (Opex)
Is this a fair comparison? The LLM development race makes it increasingly difficult to find good comparison points. After the successive iterations of ChatGPT achieved better scores on human tests like US college entrance exams and others, the focus shifted to specific AI benchmarks.
The Artificial Analysis website offers one such benchmark. DeepSeek's R1 model scores significantly higher than its V3 model, released last year. It outperforms most other models in multiple areas, not just this one. Currently, it's on par with OpenAI's latest o1 model.
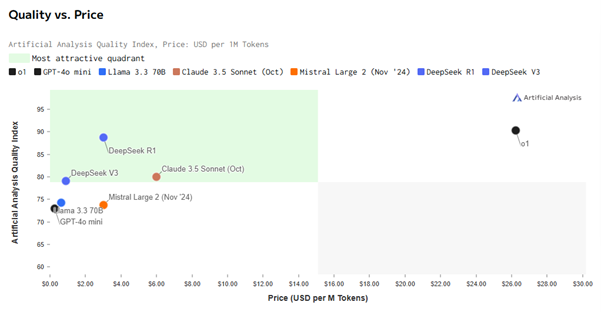
A striking difference: the cost of use. In this regard, DeepSeek leaves ChatGPT in the dust.
Users interact with LLMs via tokens. The rule of thumb is that 1 token represents 4 letters. Converted, 750 words are worth around 1,000 tokens. This allows us to calculate the cost of both input and output exchanged between users and LLMs. And that cost is 90% lower for DeepSeek.
Micro, macro, and geo
The release of R1 sent shockwaves through the tech scene. And inevitably, it sparked a strong counterreaction in the frenzied information cycle of 2025. Rumours that DeepSeek might have used more and better chips than indicated lack evidence for now. Still, we keep in mind the small chance of overly rosy projections around the model when considering the consequences. Because they are significant.
Firstly, DeepSeek appears to demonstrate that hardware is less important than thought for building robust models, and hardware manufacturers have felt the impact. The fact that a smaller player can temporarily match OpenAI's superiority erodes the sustainability of the competitive advantage of the largest AI developers. Interestingly, this doesn't necessarily have to be a problem for the largest tech players themselves. They can't help but develop "Bleeding Edge AI", and the cost of doing this might have decreased.
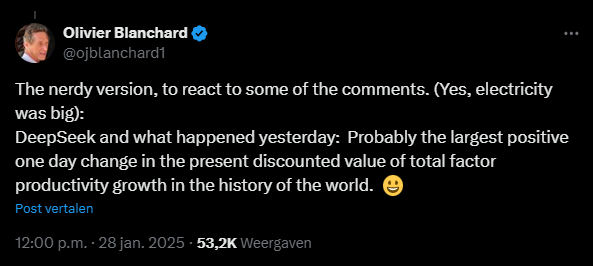
A second consequence was perfectly put by former IMF chief Olivier Blanchard in the message below on X, formerly known as Twitter. If building AI models indeed becomes much cheaper, their development and deployment will accelerate. And that's a good thing for the global economy: with the same amount of labour and capital as input, we can potentially achieve higher (or faster) growth in the future.
A third consequence is that the US chip ban might have backfired. It prohibits the export of high-performance H100-GPU chips, which were long assumed to be crucial for developing top AI models. Something the US would rather not see China do. The DeepSeek engineers were forced to work with H800-GPU chips... and succeeded. A remarkable feat of innovative entrepreneurship, especially painful for the US.
The US is now considering a U-turn. In a world where the AI genie (better models) can't be put back in the bottle, trying to hinder technological diffusion only comes at a high cost. If training costs have indeed decreased, the playing field shifts to the end-user. They need devices – smartphones, laptops, servers – to utilise these models and truly reap the benefits of the enormous potential embedded in the technology. It's almost impossible to restrict the necessary chips, so it's better to produce them yourself.
One thing is certain: One thing is certain: AI pessimists will see our future arriving even faster after this week. Let's hope everything goes well...
________________________________________
* OpenAI claims "distillation".
** DeepSeek-V3 training costs from the accompanying paper
*** Humanity's Last Exam