DeepSeek: signaal vs. ruis
2 min
Het Chinese, niet-beursgenoteerde bedrijf DeepSeek releasede enkele dagen geleden een nieuw AI-model en dat zullen we geweten hebben. Vooral de lage kostprijs van de ontwikkeling sprong in het oog en daar reageerden de beurzen niet goed op. Wat leert die release ons en hoe stellen we onze verwachtingen bij?

LLM’s (Large Language Models) groeien niet aan de bomen. De taalmodellen ontstaan door enorme hoeveelheden datapunten (een trainingsset) te verwerken tot een set van gewichten. Het zijn die gewichten die de input van een gebruiker in bijvoorbeeld het venster van een chatbot omzetten in een antwoord. Voor de huidige generaties LLM’s variëren die antwoorden nog altijd tussen indrukwekkend en … minder indrukwekkend. Maar de verdeling ervan schuift steeds vaker op naar het eerste, weg van het tweede, naarmate er steeds betere modellen opduiken.
Kapitaaluitgaven (Capex)
Hoe die verbetering gebeurt? Knappe koppen verbeteren het proces van trainingsset tot gewichten. AI-ontwikkelaars sluiten akkoorden met bijvoorbeeld uitgeverijen die unieke, kwalitatieve datasets ter beschikking stellen. AI-ontwikkelaars leren ook van elkaar en kopiëren best practices. Maar bovenal rekenen de CEO’s van vooral de grootste techspelers op de schijnbare heilige regel: ‘meer rekenkracht = betere modellen’.
Daarom vloeit er massaal geld naar de uitbouw van datacenters, investeren techspelers plots in energievoorziening en sluiten ze zelfs rechtstreeks financiële akkoorden met kerncentrales. En om die reden ook worden er voorraden grafische chips aangelegd. En net die assumptie lijkt* DeepSeek onderuit te halen met zijn recentste release. De geschatte kostprijs van de training: zo’n 5 miljoen USD**. Dat is ruim twee grootteordes minder dan wat spelers als OpenAI en Meta zouden spenderen.
Operationele kosten (Opex)
Is dat een faire vergelijking? De race bij de LLM-ontwikkeling maakt het steeds moeilijker om goede vergelijkingspunten te vinden. Nadat vooral de opeenvolgende iteraties van ChatGPT steeds betere scores lieten optekenen op menselijke proeven zoals SAT’s (gestandaardiseerde toelatingstests voor hogescholen en universiteiten in de Verenigde Staten) of andere examens, verschoof de focus naar specifieke AI-benchmarks.
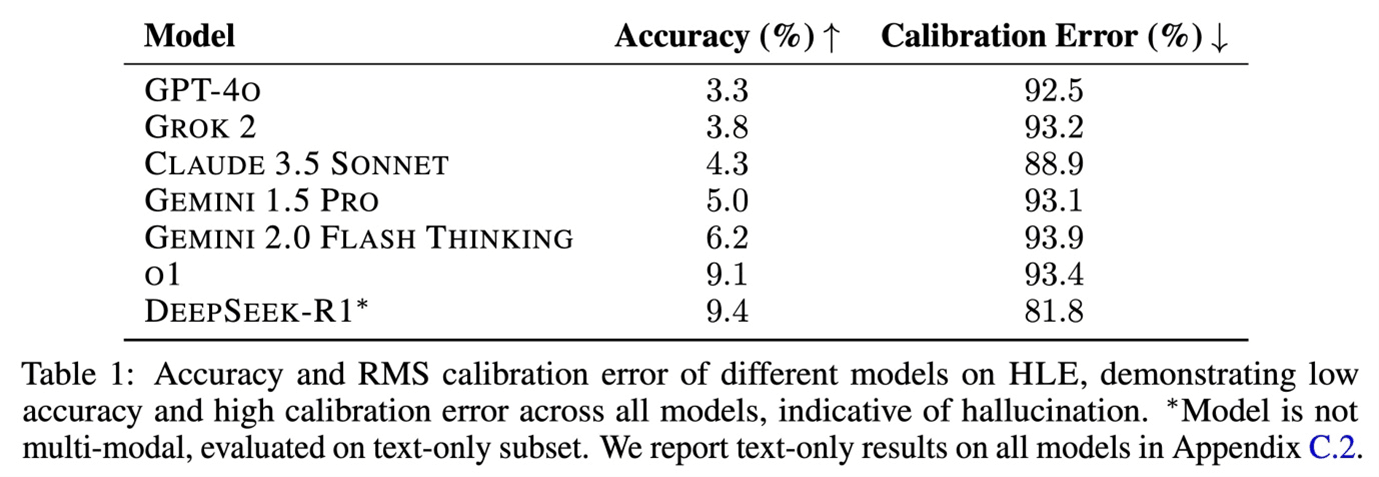
De website Artificial Analysis biedt zo één benchmark aan. DeepSeeks R1-model scoort een stuk hoger dan zijn V3-model, dat vorig jaar uitkwam. Het scoort een stuk hoger dan de meeste andere modellen en dat is niet enkel zo voor dat criterium***. Op dit moment bevindt het zich samen met het recentste o1-model van OpenAI op eenzame hoogte.
Opvallend verschil: de kostprijs van het gebruik. Daarin geeft DeepSeek ChatGPT flink het nakijken.
Gebruikers interageren met LLM’s via tokens. De vuistregel is daarbij dat 1 token 4 letters vertegenwoordigt. Omgerekend zijn 750 woorden zo’n 1.000 tokens waard. Zo kan er dus een kostprijs worden berekend voor zowel de input als de output die gebruikers uitwisselen met LLM’s. En die kostprijs ligt 90% lager bij DeepSeek.
Micro, macro en geo
De release van R1 joeg een schokgolf door de techscene. En onvermijdelijk zorgde dat in de dolgedraaide informatiecyclus van 2025 ook voor een flinke tegenreactie*. Geruchten dat DeepSeek alsnog zou hebben gebruikgemaakt van meer en betere chips dan aangegeven, missen vooralsnog bewijs. Toch houden we ook best de kleine kans op overdreven rooskleurige beeldvorming rond het model in het achterhoofd bij het doordenken van de gevolgen. Want die zijn niet min.
Ten eerste lijkt DeepSeek aan te tonen dat hardware minder belangrijk is dan gedacht om straffe modellen te bouwen en dat hebben de hardwareproducenten gevoeld. Dat een kleinere speler in staat is om de superioriteit van OpenAI (tijdelijk) te evenaren, knabbelt ook aan de duurzaamheid van het competitief voordeel van de grootste AI-ontwikkelaars. Interessant is dat dat voor de grootste techspelers zélf niet per se een probleem hoeft te zijn. Zij kunnen eigenlijk niet anders dan ‘Bleeding Edge AI’ (proberen) ontwikkelen en de kostprijs van die missie is mogelijks gekelderd.
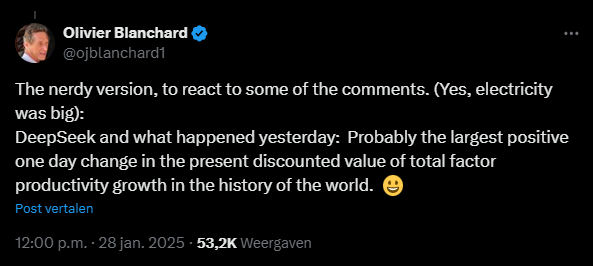
Een tweede gevolg werd prachtig verwoord door gewezen IMF-chef Olivier Blanchard in onderstaand bericht op X, het voormalige Twitter. Als de bouw van AI-modellen inderdaad zoveel goedkoper wordt, dan zal de ontwikkeling én uitrol ervan sneller gebeuren. En dat is een goede zaak voor de wereldeconomie: met evenveel arbeid en kapitaal als inputs, kunnen we in de toekomst potentieel een hogere (of eerder sneller een hogere) groei realiseren.
Een derde gevolg is dat de Amerikaanse chipban mogelijk averechts werkte. Die verbiedt immers de export van performante H100-GPU-chips. Chips, waarvan lang werd aangenomen dat ze cruciaal zijn om top-AI-modellen te ontwikkelen. Iets wat de VS China liever niet zag doen. De DeepSeek-ingenieurs gingen mede daarom noodgedwongen aan de slag met de H800-GPU-chips … en slaagden daar nog in ook. Een knap staaltje innovatief ondernemerschap, extra pijnlijk voor de VS natuurlijk.
Die laatsten overwegen nu best hun kar te keren. In een wereld waarin de AI-geest (betere modellen) niet in de fles blijft, heeft technologische diffusie tegengaan enkel een hoge kostprijs. Als de trainingskosten inderdaad gekelderd zijn, verschuift het speelveld nu naar de eindgebruiker. Die heeft toestellen – smartphones, laptops, servers – nodig om die modellen te kunnen benutten en écht de vruchten te plukken van het enorme potentieel dat in de technologie vervat zit. Het is schier onmogelijk om de benodigde chips te beperken en dus kan je ze beter zelf gaan produceren.
Eén ding is zeker: AI-doomdenkers zien ons na deze week weer wat sneller vooruitmarcheren. Als dat maar goed gaat.
_____________
* OpenAI klaagt “distillatie” aan.
** DeepSeek-V3-trainingskosten uit de begeleidende paper