Deepseek: signal vs bruit
2 min
L’entreprise chinoise non cotée DeepSeek a lancé il y a quelques jours un nouveau modèle d'IA, et cela n'est pas passé inaperçu. Ce qui a particulièrement retenu l'attention, c'est le faible coût de développement, ce qui n'a pas été bien accueilli par les marchés boursiers. Que nous apprend cette sortie et comment devons-nous ajuster nos attentes ?

Les modèles de langage (« Large Language Models » ou « LLM ») ne poussent pas sur les arbres.
Ils émergent en traitant d'énormes quantités de données (un ensemble d’entraînement) pour générer un ensemble de poids. Ce sont ces poids qui transforment l'entrée d'un utilisateur (par exemple dans la fenêtre d’un chatbot) en une réponse. Pour les générations actuelles de LLM, ces réponses varient encore entre impressionnant et… moins impressionnant. Mais avec l’apparition de modèles toujours meilleurs, la répartition des performances penche de plus en plus vers l’impressionnant.
Dépenses d’investissement (Capex)
Comment cette amélioration est-elle obtenue ? Des experts perfectionnent le processus qui va des ensembles d'entraînement aux poids. Les développeurs d'IA concluent des accords avec des éditeurs pour accéder à des ensembles de données uniques et de qualité.
Les acteurs de l’IA apprennent les uns des autres et copient les meilleures pratiques.
Mais surtout, les PDG des grandes entreprises technologiques s’appuient sur une règle quasi sacrée : « plus de puissance de calcul = meilleurs modèles ».
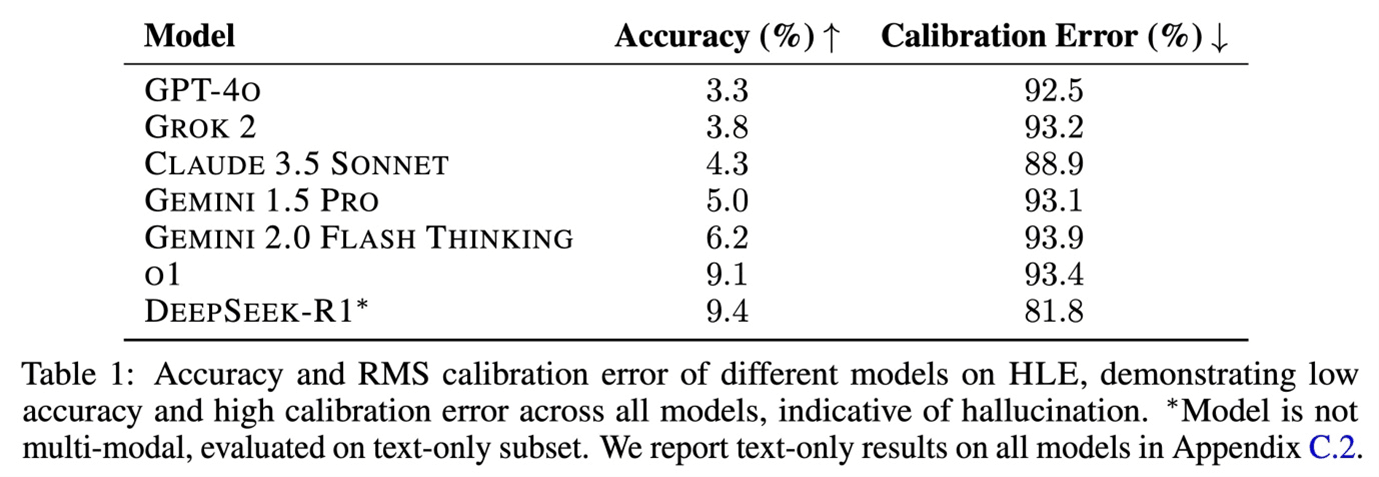
C'est pourquoi des sommes colossales sont investies dans la construction de centres de données, dans l’approvisionnement énergétique, et même dans des accords financiers directs avec des centrales nucléaires. C’est aussi pour cette raison que des stocks massifs de puces graphiques sont constitués. Et c’est précisément cette hypothèse que DeepSeek semble remettre en cause avec sa dernière sortie. Le coût estimé de l'entraînement : environ 5 millions de dollars, soit cent fois moins que ce que des acteurs comme OpenAI ou Meta dépenseraient.
Coûts opérationnels (Opex)
Est-ce une comparaison équitable ? La course au développement des LLM rend de plus en plus difficile la recherche de points de comparaison pertinents. Après que les versions successives de ChatGPT ont atteint de meilleurs scores aux tests humains (comme le SAT, un test d’admission standardisé pour les hautes écoles et les universités aux États-Unis), l’attention s’est déplacée vers des benchmarks IA spécifiques.
Le site Artificial Analysis propose justement un tel benchmark. Le modèle R1 de DeepSeek surpasse largement son modèle V3 sorti l’an dernier, et il surclasse aussi la plupart des autres modèles, y compris sur d'autres critères*. Actuellement, il se situe au même niveau que le tout dernier modèle o1 d'OpenAI.
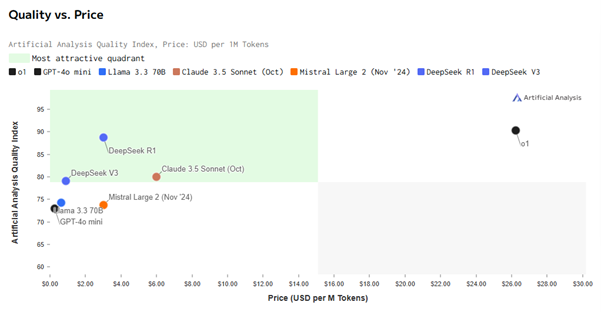
Une différence frappante : le coût d’utilisation. Sur ce point, DeepSeek surpasse ChatGPT de manière significative. Les utilisateurs interagissent avec les LLM via des tokens. En règle générale, 1 token équivaut à 4 lettres, soit environ 1.000 tokens pour 750 mots. Cela permet de calculer un coût tant pour l’entrée que pour la sortie des interactions avec un LLM. Et sur ce point, DeepSeek est 90% moins cher.
Micro, macro et géopolitique
Le lancement de R1 a provoqué une onde de choc dans le monde de la tech, entraînant inévitablement une forte contre-réaction dans le cycle d’information ultra-rapide de 2025. Des rumeurs circulent selon lesquelles DeepSeek aurait en réalité utilisé plus de puces et de meilleure qualité qu’annoncé, mais aucun élément ne le prouve pour l’instant. Il reste néanmoins une faible probabilité que l’entreprise ait enjolivé la réalité. Les conséquences, elles, sont bien réelles :
DeepSeek prouve que le matériel est peut-être moins crucial qu'on ne le pensait pour créer des modèles puissants, ce que les fabricants de puces ont bien ressenti. Le fait qu’un acteur plus petit puisse temporairement égaler OpenAI remet en question l’avantage concurrentiel des géants de l’IA. Pour ces grandes entreprises, cependant, cela n’est pas nécessairement un problème : elles n’ont pas d’autre choix que d’innover en « Bleeding Edge AI », et si le coût de cette mission chute, cela pourrait les avantager.
Une deuxième conséquence a été parfaitement bien résumée par l’ancien chef du FMI, Olivier Blanchard, dans un message posté sur X (ex-Twitter). Si l’IA devient moins coûteuse à développer, son adoption sera plus rapide. Cela signifie une accélération de la croissance économique mondiale, car avec les mêmes ressources humaines et financières, on pourra produire plus.
Une troisième conséquence est que m’interdiction américaine des puces a peut-être eu l’effet inverse. Les États-Unis ont en effet interdit l’exportation de puces H100-GPU vers la Chine, pensant qu’elles étaient indispensables pour développer des modèles IA avancés. Résultat : les ingénieurs de DeepSeek ont été contraints d’utiliser des H800-GPU… et ils ont réussi. Un exploit d’innovation qui représente un revers stratégique pour les États-Unis.
Désormais, Washington doit reconsidérer sa stratégie. Dans un monde où l’IA progresse inexorablement, bloquer la diffusion technologique ne fait qu’augmenter les coûts. Avec la baisse des coûts d'entraînement, le nouvel enjeu devient l’utilisateur final. Il aura besoin d’appareils – smartphones, laptops, serveurs – pour exploiter pleinement ces modèles et bénéficier de leur potentiel. Et comme restreindre l’accès aux puces devient quasi impossible, autant les produire soi-même.
Une chose est sûre : les pessimistes de l’IA voient notre futur arriver encore plus vite après cette semaine. Espérons que tout se passe bien…
_____________
* Coûts d’entraînement de DeepSeek V3 tirés du document annexe