Wat als … AI de wetenschap versnelt?
5 min
Steeds slimmere AI belooft productiviteitswinsten in veel sectoren. Maar tijdswinst is slechts een fractie van hoe de technologie ons leven kan veranderen. Zorgt AI straks voor een tsunami aan wetenschappelijke ontdekkingen? Dan moeten wetenschappelijke resultaten misschien wel anders gecommuniceerd worden. En dat heeft voor- en nadelen.

"Als het niet baat iets eenmaal te doen, doet het dat ook niet bij tweemaal, driemaal … of zelfs ooit."
Paul Samuelson, 1979
Niet direct een zin die je verwacht in een economische paper. Nochtans schreef Paul Samuelson zo zijn standpunt over optimaal investeringsgedrag neer. Goed tien jaar na zijn bekroning door het Nobelcomité was Samuelson in een bittere discussie beland met onder meer Harry Markowitz. Inzet? Het Kelly-criterium. Dat is een berekeningswijze om voor een onzekere investering te bepalen welk deel van je vermogen je er best insteekt om de opbrengst te maximaliseren.
Het Kelly-criterium vereist echter een enorme risicotolerantie, gezien er een groot deel van het vermogen ingezet wordt … en dus ook verloren kan gaan. Samuelson maakte brandhout van het idee: hij toonde wiskundig aan dat lang niet iedereen zoveel risico verdraagt.
Samuelson, met KO
Maar veel krachtiger was de paper uit 1979 ‘Why we should not make mean log of wealth big though years to act are long’. Daarin doet hij zijn betoog nog eens over, enkel gebruikmakend van woorden met één lettergreep. De boodschap voor zijn tegenhangers: ik gebruik eenvoudige taal … want jullie zijn dommeriken.
Score: Samuelson won, met knock-out … althans binnen de academische wereld. Grote investeerders (en gokkers) maakten nadien wel gretig gebruik van het criterium en aanverwante ideeën.
Het is twijfelachtig of AI Samuelsons schrijfsel zou hebben geïnterpreteerd zoals zijn collega’s toen. Die konden de paper plaatsen binnen de literatuur, maar begrepen vooral de context van de discussie en hoe krachtig Samuelsons signaal was. Hoewel dit een uitzonderlijk document is, stelt het probleem zich vaker: Hoe zorgen we ervoor dat AI wetenschappelijke papers begrijpt?
Een datacenter vol genieën … en scheidsrechters
Enkele onderzoekers schreven een stukje software, OpenEval. Dat deden ze door duizenden eerste versies van papers te vergelijken met de opmerkingen die zogenaamde scheidsrechters erop gaven. Die scheidsrechters zijn de poortwachters langs wie onderzoekers met hun werk passeren voor ze in wetenschappelijke magazines gepubliceerd geraken.
De onderzoekers gebruikten LLM’s om uit de draft papers claims te destilleren. Die claims zijn in essentie de onderzoeksresultaten die in verschillende vormen (grafieken, tabellen, doorlopende tekst) in de documenten verborgen zijn. Vervolgens lieten ze OpenEval de resultaten evalueren. Daaruit bleek dat 80% van de onderzochte resultaten op eenzelfde manier werd geëvalueerd door de software als door de scheidsrechters. Slechts in minder dan 1% van de gevallen was de evaluatie drastisch verschillend.
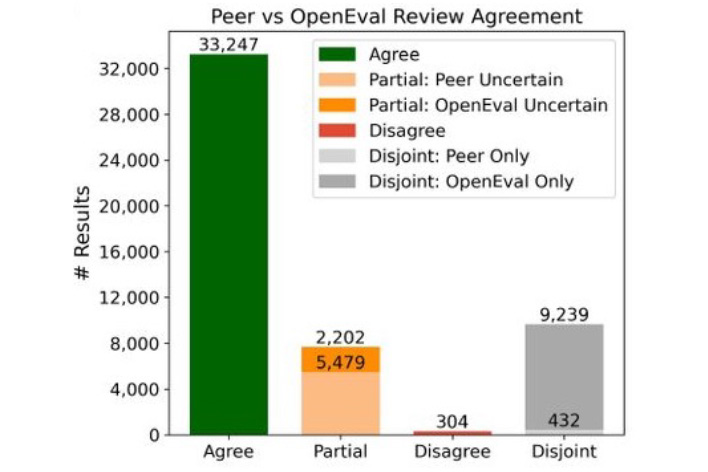
Dat is geen verrassing. AI wordt steeds bruikbaarder voor wetenschappelijk onderzoek. Recent nog stak de nukkige econoom John Cochrane een lofrede af over ‘refine’. De opmerkingen die de tool gaf over zijn werk behoren tot “de beste die hij in zijn hele carrière kreeg”, aldus Cochrane, toch geen groentje in het vakgebied.
De conclusie van de auteurs is dan ook dat AI-gedreven evaluaties zeer beloftevol zijn. Vandaag zijn de scheidsrechters vaak slecht of onbetaalde professoren die feedback geven op nieuwe inzendingen binnen hun vakgebied. Het proces verloopt traag en kan erg frustrerend aanvoelen voor (onervaren) onderzoekers. Die moeten vaak hun afgerond onderzoek op andere manieren uitschrijven, om zo de goedkeuring van de scheidsrechters te bekomen.
AI zou dit dus flink kunnen versnellen. Maar zijn de traditionele papers dan wel het geschiktste formaat om aan wetenschap te doen?
Een nieuwe standaard dan maar?
De ontwikkelaars van OpenEval stellen immers vast dat het verzamelen van claims in reeds gepubliceerd werk erg veel rekencapaciteit vergt van de LLM’s en lang niet foutloos verloopt. Veel liever dan achteraf een vertaalslag te maken, zien zij aan de bron een andere formatering van de onderzoeksresultaten. Daarom pleiten ze ervoor om academisch werk direct “machineleesbaar” te maken. Een soort nieuwe standaard voor academische papers dus.
Dat biedt enkele duidelijke voordelen: een databank van claims verlaagt drastisch de kost om te achterhalen welke hypotheses eerder werden onderzocht. Ook kunnen de claims in zo’n databank rechtstreeks gelinkt worden aan de gebruikte methode en achterliggende data, waardoor ze geloofwaardiger zijn.
Maar wanneer wetenschappelijk werk uitsluitend via lijsten van claims wordt gecommuniceerd, hangt daar ook een groot nadeel aan vast.
Samuelsons schrijfsel deed immers meer dan alleen de resultaten van zijn werk belichten. De gekozen vorm – heel eenvoudige woorden – droeg in belangrijke mate bij aan hoe wetenschappers nadien met de ideeën aan de slag gingen. En dat is een belangrijk inzicht.
Wetenschappelijke documenten dienen vandaag niet enkel om claims over te brengen. Ze vertellen vaak een specifiek verhaal over het gevoerde onderzoek, de reden ervan en de relevantie van de resultaten. En dat verhaal bepaalt mee of en hoe toekomstig onderzoek zal gevoerd worden.
Zo was het de beroemde ‘twee Jannen’-paper over marktmacht en de economische implicaties ervan, die mij deed kiezen voor Industriële Organisatie als specialisatie in mijn onderzoeksmaster. Want papers strijden natuurlijk – net als alle informatiedragers – met elkaar voor de schaarse aandacht van de consument, lezer en potentiële onderzoekscollega. Samuelson deed dus eigenlijk aan marketing.
De enige constante is verandering
Wat de academische paper vandaag overkomt, is eigenlijk niets anders dan het bekende Silicon Valley-motto “ontbundel, herbundel, herhaal”.
Tot voor kort zorgden papers ervoor dat onderzoeksresultaten werden gedeeld op zo’n manier dat scheidsrechters ze konden evalueren en onderzoekers er mee aan de slag konden en wilden gaan. Om het potentieel van AI meer te benutten, zou het scheiden van deze aspecten nuttig kunnen zijn. Dat kan door, zoals de OpenEval-ontwikkelaars voorstellen, een nieuwe standaard te ontwikkelen. Maar evident is dat natuurlijk niet.

Academische publicaties zijn een erg gesloten systeem. Een handvol uitgevers beheerst de markt. Zij rekenen onderzoekers, of juister: onderzoeksinstellingen, handenvol geld voor toegang tot wetenschappelijk onderzoek. Een systeem dat op veel kritiek stuit bij de gebruikers, die vaak gratis (of soms zelfs betalend) het product leveren waar ze zelf voor aangerekend worden.
Sommigen werken hard om daar verandering in te brengen. Bijvoorbeeld door vrij toegankelijke publicatiesystemen op te zetten, zoals Arxiv. Maar ook door de regels te breken, zoals de wetenschappelijke piratenkoningin Alexandra Asanovna Elbakyan.
Het laatste woord is aan AI zelf. Consensus vergemakkelijkt vandaag al het werk van onderzoekers. Het verwerkt miljoenen papers om een eenvoudige ja/nee-vraag onderbouwd te beantwoorden.
De vraag “Versnelt wetenschappelijk onderzoek wanneer AI eenvoudiger papers kan lezen?” krijgt van Consensus een klassiek economisch antwoord: “Incentives matter”.
Dat had deze econoom alvast niet beter kunnen samenvatten.