Et si… l’IA accélérait la science ?
5 min
L’IA, toujours plus performante, promet des gains de productivité dans de nombreux secteurs. Mais gagner du temps n’est qu’une infime partie de ce que cette technologie pourrait changer dans nos vies. L’IA pourrait-elle déclencher un raz-de-marée de découvertes scientifiques ? Alors peut-être faudrait-il repenser la manière de communiquer les résultats. Cela a des avantages… comme des inconvénients.

"Si une chose ne vaut pas la peine d’être faite une fois, elle ne le vaut pas davantage deux, trois fois… ou jamais."
Paul Samuelson, 1979
Ce n’est pas le genre de phrase que l’on s’attend à lire dans un article économique. Pourtant, c’est ainsi que Samuelson, une décennie après son Nobel, couchait sur papier sa position sur le comportement d’investissement optimal. À l’époque, il était engagé dans une dispute acerbe avec Harry Markowitz, entre autres. Le sujet ? Le critère de Kelly – une méthode de calcul déterminant, pour un investissement incertain, quelle part de son capital il faut engager pour maximiser le rendement.
Or, ce critère exige une tolérance au risque colossale, puisque la mise (et donc la perte potentielle) est conséquente. Samuelson en a fait des cendres : il a démontré mathématiquement que bien peu d’investisseurs supportent un tel niveau de risque.
Samuelson par KO
Mais le document de 1979 « Why we should not make mean log of wealth big though years to act are long » était beaucoup plus puissant. Il y reprend son discours, en utilisant uniquement des mots d’une seule syllabe. Message à ses adversaires : « J’emploie un langage simple… parce que vous êtes des idiots. »
Résultat : victoire par KO pour Samuelson – du moins dans le monde académique. Les grands investisseurs (et les parieurs) ont ensuite adopté avec enthousiasme ce critère et ses dérivés.
Douteux, en revanche, que l’IA ait interprété ce texte comme l’ont fait ses collègues. Ceux-ci le situaient dans son contexte littéraire, mais surtout dans celui de la polémique – et mesuraient la force du signal envoyé par Samuelson. Bien que ce document soit exceptionnel, le problème est récurrent : comment faire en sorte que l’IA comprenne les articles scientifiques ?
Un datacenter rempli de génies… et d’arbitres
Des chercheurs ont développé le logiciel OpenEval. Pour ce faire, ils ont comparé des milliers de premières versions de documents aux remarques formulées par les « arbitres », ces gardiens qui évaluent les travaux avant publication dans les revues scientifiques.
Grâce à des LLM, ils ont extrait des « claims » (les résultats de recherche, disséminés sous forme de graphiques, tableaux ou texte) des brouillons. Puis OpenEval les a évalués. Résultat : 80% des évaluations correspondaient à celles des arbitres humains. Moins de 1% présentaient des écarts majeurs.
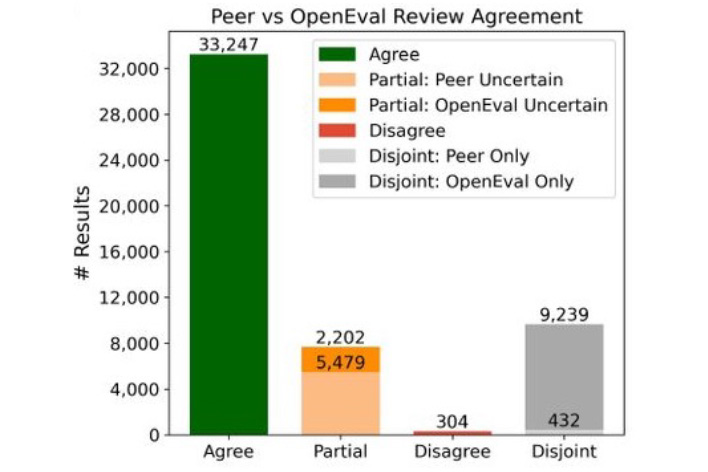
Ce n’est pas une surprise. L’IA s’impose comme un outil précieux pour la recherche. Récemment encore, l’économiste John Cochrane a salué « Refine », dont les suggestions sur ses travaux figurent, selon lui, « parmi les meilleures de sa carrière » – et Cochrane n’est pas un novice.
Les auteurs en concluent que l’évaluation par IA est prometteuse. Aujourd’hui, les arbitres – souvent des professeurs mal ou non rémunérés – rendent des avis lents et frustrants pour les chercheurs, contraints de réécrire leurs travaux pour obtenir une validation.
L’IA pourrait accélérer ce processus. Mais le format traditionnel de l’article est-il encore adapté à la science ?
Un nouveau standard ?
Les développeurs d’OpenEval constatent que l’extraction des claims dans les articles publiés exige une puissance de calcul colossale des LLM, avec des erreurs résiduelles. Plutôt que de traduire a posteriori, ils prônent une reformulation à la source : ils plaident pour que le travail académique soit directement « lisible par machine » dès leur création. Une norme académique inédite, en somme.
Cela présente quelques avantages évidents : une base de données de claims réduirait drastiquement le coût de vérification des hypothèses existantes. Et ces claims, liés aux méthodes et données sous-jacentes, gagneraient en crédibilité.
Mais un inconvénient majeur persiste : un article scientifique ne se réduit pas à une liste de résultats.
La forme choisie – des mots très simples – a largement contribué à la façon dont les scientifiques ont ensuite travaillé sur les idées. Et c’est un point important.
Aujourd’hui, les documents scientifiques ne servent pas seulement à transmettre des conclusions. Ils racontent souvent une histoire spécifique sur la recherche menée, ses motivations et la pertinence des résultats. Et cette narration détermine en partie si, et comment, les recherches futures seront orientées.
Ainsi, c’est le célèbre article des « deux Jan » sur le pouvoir de marché et ses implications économiques qui m’a poussé à choisir l’Organisation industrielle comme spécialisation dans mon master de recherche. Car les articles, comme tous les supports d’information, rivalisent pour capter l’attention rare des consommateurs, des lecteurs et des futurs collègues chercheurs. Samuelson faisait, en somme, du marketing.
La seule constante, c’est le changement
Ce qui se passe aujourd’hui dans l’article académique n’est en fait rien d’autre que l’application du célèbre adage de la Silicon Valley « désagréger, réagréger, répéter ».
Jusqu’à récemment, les publications permettaient de partager les résultats de recherche de manière à ce que les évaluateurs puissent les analyser et que les chercheurs puissent s’en emparer. Pour mieux exploiter le potentiel de l’IA, séparer ces fonctions pourrait s’avérer utile – comme le proposent les développeurs d’OpenEval avec une nouvelle norme. Mais rien n’est moins évident.

Les publications académiques sont un système très fermé. Une poignée d’éditeurs domine le marché et facture aux chercheurs – ou plutôt à leurs institutions – des sommes exorbitantes pour accéder aux travaux scientifiques. Un modèle vivement critiqué par ses utilisateurs, qui fournissent souvent gratuitement (voire en payant) le contenu pour lequel ils sont ensuite facturés.
Certains œuvrent à changer la donne, par exemple en créant des plateformes en accès libre comme Arxiv. D’autres bousculent les règles, à l’image de la « reine des pirates scientifiques », Alexandra Asanovna Elbakyan.
Le dernier mot revient à l’IA elle-même. Consensus facilite déjà le travail des chercheurs : il analyse des millions d’articles pour répondre par un simple oui ou non à une question complexe.
À la question « L’IA accélère-t-elle la recherche scientifique en simplifiant la lecture des articles ? », Consensus répond par un classique de l’économie : « Les incitations comptent ».
Un économiste n’aurait pas mieux résumé.